Build a dlt pipeline
This tutorial introduces you to foundational dlt concepts, demonstrating how to build a custom data pipeline that loads data from pure Python data structures to DuckDB. It starts with a simple example and progresses to more advanced topics and usage scenarios.
What you will learn
- Loading data from a list of Python dictionaries into DuckDB.
- Low level API usage with built-in HTTP client.
- Understand and manage data loading behaviors.
- Incrementally load new data and deduplicate existing data.
- Dynamic resource creation and reducing code redundancy.
- Group resources into sources.
- Securely handle secrets.
- Make reusable data sources.
Prerequisites
- Python 3.9 or higher installed
- Virtual environment set up
Installing dlt
Before we start, make sure you have a Python virtual environment set up. Follow the instructions in the installation guide to create a new virtual environment and install dlt.
Verify that dlt is installed by running the following command in your terminal:
dlt --version
Quick start
For starters, let's load a list of Python dictionaries into DuckDB and inspect the created dataset. Here is the code:
import dlt
data = [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
pipeline = dlt.pipeline(
pipeline_name="quick_start", destination="duckdb", dataset_name="mydata"
)
load_info = pipeline.run(data, table_name="users")
print(load_info)
When you look at the code above, you can see that we:
- Import the
dltlibrary. - Define our data to load.
- Create a pipeline that loads data into DuckDB. Here we also specify the
pipeline_nameanddataset_name. We'll use both in a moment. - Run the pipeline.
Save this Python script with the name quick_start_pipeline.py and run the following command:
python quick_start_pipeline.py
The output should look like:
Pipeline quick_start completed in 0.59 seconds
1 load package(s) were loaded to destination duckdb and into dataset mydata
The duckdb destination used duckdb:////home/user-name/quick_start/quick_start.duckdb location to store data
Load package 1692364844.460054 is LOADED and contains no failed jobs
dlt just created a database schema called mydata (the dataset_name) with a table users in it.
Explore the data
To allow sneak peek and basic discovery you can take advantage of built-in integration with Strealmit:
dlt pipeline quick_start show
quick_start is the name of the pipeline from the script above. If you do not have Streamlit installed yet do:
pip install streamlit
Now you should see the users table:
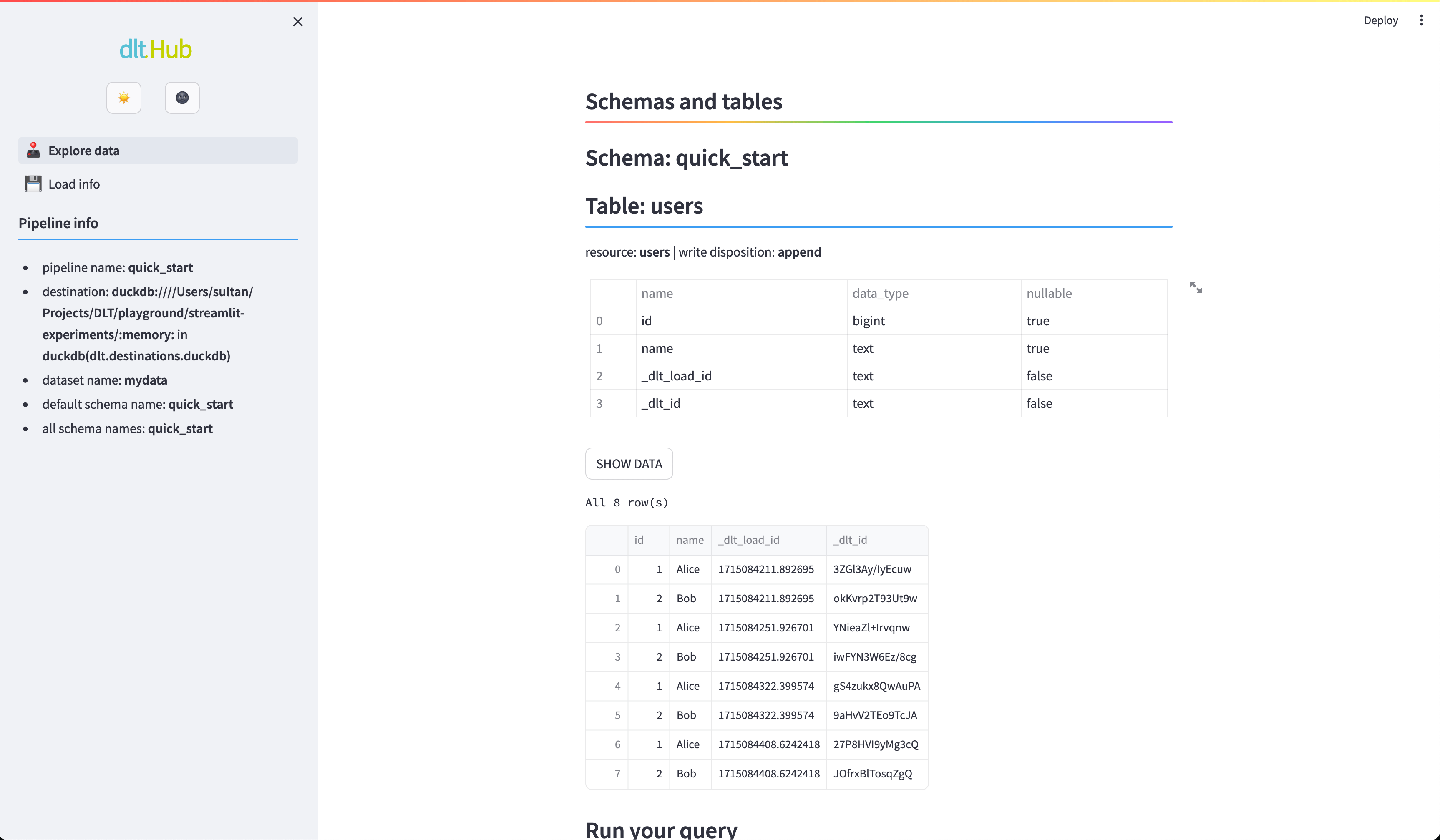 Streamlit Explore data. Schema and data for a test pipeline “quick_start”.
Streamlit Explore data. Schema and data for a test pipeline “quick_start”.
dlt works in Jupyter Notebook and Google Colab! See our Quickstart Colab Demo.
Looking for source code of all the snippets? You can find and run them from this repository.
Now that you have a basic understanding of how to get started with dlt, you might be eager to dive deeper. For that we need to switch to a more advanced data source - the GitHub API. We will load issues from our dlt-hub/dlt repository.
This tutorial uses GitHub REST API for demonstration purposes only. If you need to read data from a REST API, consider using the dlt's REST API source. Check out the REST API source tutorial for quick start or REST API source reference for more details.
Create a pipeline
First, we need to create a pipeline. Pipelines are the main building blocks of dlt and are used to load data from sources to destinations. Open your favorite text editor and create a file called github_issues.py. Add the following code to it:
import dlt
from dlt.sources.helpers import requests
# Specify the URL of the API endpoint
url = "https://api.github.com/repos/dlt-hub/dlt/issues"
# Make a request and check if it was successful
response = requests.get(url)
response.raise_for_status()
pipeline = dlt.pipeline(
pipeline_name="github_issues",
destination="duckdb",
dataset_name="github_data",
)
# The response contains a list of issues
load_info = pipeline.run(response.json(), table_name="issues")
print(load_info)
Here's what the code above does:
- It makes a request to the GitHub API endpoint and checks if the response is successful.
- Then it creates a dlt pipeline with the name
github_issuesand specifies that the data should be loaded to theduckdbdestination and thegithub_datadataset. Nothing gets loaded yet. - Finally, it runs the pipeline with the data from the API response (
response.json()) and specifies that the data should be loaded to theissuestable. Therunmethod returns aLoadInfoobject that contains information about the loaded data.
Run the pipeline
Save github_issues.py and run the following command:
python github_issues.py
Once the data has been loaded, you can inspect the created dataset using the Streamlit app:
dlt pipeline github_issues show
Append or replace your data
Try running the pipeline again with python github_issues.py. You will notice that the issues table contains two copies of the same data. This happens because the default load mode is append. It is very useful, for example, when you have daily data updates and you want to ingest them.
To get the latest data, we'd need to run the script again. But how to do that without duplicating the data?
One option is to tell dlt to replace the data in existing tables in the destination by using replace write disposition. Change the github_issues.py script to the following:
import dlt
from dlt.sources.helpers import requests
# Specify the URL of the API endpoint
url = "https://api.github.com/repos/dlt-hub/dlt/issues"
# Make a request and check if it was successful
response = requests.get(url)
response.raise_for_status()
pipeline = dlt.pipeline(
pipeline_name='github_issues',
destination='duckdb',
dataset_name='github_data',
)
# The response contains a list of issues
load_info = pipeline.run(
response.json(),
table_name="issues",
write_disposition="replace" # <-- Add this line
)
print(load_info)
Run this script twice to see that issues table still contains only one copy of the data.
What if the API has changed and new fields get added to the response?
dlt will migrate your tables!
See the replace mode and table schema migration in action in our Schema evolution colab demo.
Learn more:
Declare loading behavior
So far we have been passing the data to the run method directly. This is a quick way to get started. However, frequently, you receive data in chunks, and you want to load it as it arrives. For example, you might want to load data from an API endpoint with pagination or a large file that does not fit in memory. In such cases, you can use Python generators as a data source.
You can pass a generator to the run method directly or use the @dlt.resource decorator to turn the generator into a dlt resource. The decorator allows you to specify the loading behavior and relevant resource parameters.
Load only new data (incremental loading)
Let's improve our GitHub API example and get only issues that were created since last load.
Instead of using replace write disposition and downloading all issues each time the pipeline is run, we do the following:
import dlt
from dlt.sources.helpers import requests
@dlt.resource(table_name="issues", write_disposition="append")
def get_issues(
created_at=dlt.sources.incremental("created_at", initial_value="1970-01-01T00:00:00Z")
):
# NOTE: we read only open issues to minimize number of calls to the API.
# There's a limit of ~50 calls for not authenticated Github users.
url = (
"https://api.github.com/repos/dlt-hub/dlt/issues"
"?per_page=100&sort=created&directions=desc&state=open"
)
while True:
response = requests.get(url)
response.raise_for_status()
yield response.json()
# Stop requesting pages if the last element was already
# older than initial value
# Note: incremental will skip those items anyway, we just
# do not want to use the api limits
if created_at.start_out_of_range:
break
# get next page
if "next" not in response.links:
break
url = response.links["next"]["url"]
pipeline = dlt.pipeline(
pipeline_name="github_issues_incremental",
destination="duckdb",
dataset_name="github_data_append",
)
load_info = pipeline.run(get_issues)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
Let's take a closer look at the code above.
We use the @dlt.resource decorator to declare the table name into which data will be loaded and specify the append write disposition.
We request issues for dlt-hub/dlt repository ordered by created_at field (descending) and yield them page by page in get_issues generator function.
We also use dlt.sources.incremental to track created_at field present in each issue to filter in the newly created.
Now run the script. It loads all the issues from our repo to duckdb. Run it again, and you can see that no issues got added (if no issues were created in the meantime).
Now you can run this script on a daily schedule and each day you’ll load only issues created after the time of the previous pipeline run.
Between pipeline runs, dlt keeps the state in the same database it loaded data to.
Peek into that state, the tables loaded and get other information with:
dlt pipeline -v github_issues_incremental info
Learn more:
- Declare your resources and group them in sources using Python decorators.
- Set up "last value" incremental loading.
- Inspect pipeline after loading.
dltcommand line interface.
Update and deduplicate your data
The script above finds new issues and adds them to the database.
It will ignore any updates to existing issue text, emoji reactions etc.
To get always fresh content of all the issues you combine incremental load with merge write disposition,
like in the script below.
import dlt
from dlt.sources.helpers import requests
@dlt.resource(
table_name="issues",
write_disposition="merge",
primary_key="id",
)
def get_issues(
updated_at=dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
# NOTE: we read only open issues to minimize number of calls to
# the API. There's a limit of ~50 calls for not authenticated
# Github users
url = (
"https://api.github.com/repos/dlt-hub/dlt/issues"
f"?since={updated_at.last_value}&per_page=100&sort=updated"
"&directions=desc&state=open"
)
while True:
response = requests.get(url)
response.raise_for_status()
yield response.json()
# Get next page
if "next" not in response.links:
break
url = response.links["next"]["url"]
pipeline = dlt.pipeline(
pipeline_name="github_issues_merge",
destination="duckdb",
dataset_name="github_data_merge",
)
load_info = pipeline.run(get_issues)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
Above we add primary_key argument to the dlt.resource() that tells dlt how to identify the issues in the database to find duplicates which content it will merge.
Note that we now track the updated_at field — so we filter in all issues updated since the last pipeline run (which also includes those newly created).
Pay attention how we use since parameter from GitHub API
and updated_at.last_value to tell GitHub to return issues updated only after the date we pass. updated_at.last_value holds the last updated_at value from the previous run.
Learn more about merge write disposition.
Using pagination helper
In the previous examples, we used the requests library to make HTTP requests to the GitHub API and handled pagination manually. dlt has the built-in REST client that simplifies API requests. We'll pick the paginate() helper from it for the next example. The paginate function takes a URL and optional parameters (quite similar to requests) and returns a generator that yields pages of data.
Here's how the updated script looks:
import dlt
from dlt.sources.helpers.rest_client import paginate
@dlt.resource(
table_name="issues",
write_disposition="merge",
primary_key="id",
)
def get_issues(
updated_at=dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
for page in paginate(
"https://api.github.com/repos/dlt-hub/dlt/issues",
params={
"since": updated_at.last_value,
"per_page": 100,
"sort": "updated",
"direction": "desc",
"state": "open",
},
):
yield page
pipeline = dlt.pipeline(
pipeline_name="github_issues_merge",
destination="duckdb",
dataset_name="github_data_merge",
)
load_info = pipeline.run(get_issues)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
Let's zoom in on the changes:
- The
whileloop that handled pagination is replaced with reading pages from thepaginate()generator. paginate()takes the URL of the API endpoint and optional parameters. In this case, we pass thesinceparameter to get only issues updated after the last pipeline run.- We're not explicitly setting up pagination,
paginate()handles it for us. Magic! Under the hood,paginate()analyzes the response and detects the pagination method used by the API. Read more about pagination in the REST client documentation.
If you want to take full advantage of the dlt library, then we strongly suggest that you build your sources out of existing building blocks:
To make most of dlt, consider the following:
Use source decorator
In the previous step, we loaded issues from the GitHub API. Now we'll load comments from the API as well. Here's a sample dlt resource that does that:
import dlt
from dlt.sources.helpers.rest_client import paginate
@dlt.resource(
table_name="comments",
write_disposition="merge",
primary_key="id",
)
def get_comments(
updated_at = dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
for page in paginate(
"https://api.github.com/repos/dlt-hub/dlt/comments",
params={"per_page": 100}
):
yield page
We can load this resource separately from the issues resource, however loading both issues and comments in one go is more efficient. To do that, we'll use the @dlt.source decorator on a function that returns a list of resources:
@dlt.source
def github_source():
return [get_issues, get_comments]
github_source() groups resources into a source. A dlt source is a logical grouping of resources. You use it to group resources that belong together, for example, to load data from the same API. Loading data from a source can be run in a single pipeline. Here's what our updated script looks like:
import dlt
from dlt.sources.helpers.rest_client import paginate
@dlt.resource(
table_name="issues",
write_disposition="merge",
primary_key="id",
)
def get_issues(
updated_at = dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
for page in paginate(
"https://api.github.com/repos/dlt-hub/dlt/issues",
params={
"since": updated_at.last_value,
"per_page": 100,
"sort": "updated",
"directions": "desc",
"state": "open",
}
):
yield page
@dlt.resource(
table_name="comments",
write_disposition="merge",
primary_key="id",
)
def get_comments(
updated_at = dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
for page in paginate(
"https://api.github.com/repos/dlt-hub/dlt/comments",
params={
"since": updated_at.last_value,
"per_page": 100,
}
):
yield page
@dlt.source
def github_source():
return [get_issues, get_comments]
pipeline = dlt.pipeline(
pipeline_name='github_with_source',
destination='duckdb',
dataset_name='github_data',
)
load_info = pipeline.run(github_source())
print(load_info)
Dynamic resources
You've noticed that there's a lot of code duplication in the get_issues and get_comments functions. We can reduce that by extracting the common fetching code into a separate function and use it in both resources. Even better, we can use dlt.resource as a function and pass it the fetch_github_data() generator function directly. Here's the refactored code:
import dlt
from dlt.sources.helpers.rest_client import paginate
BASE_GITHUB_URL = "https://api.github.com/repos/dlt-hub/dlt"
def fetch_github_data(endpoint, params={}):
url = f"{BASE_GITHUB_URL}/{endpoint}"
return paginate(url, params=params)
@dlt.source
def github_source():
for endpoint in ["issues", "comments"]:
params = {"per_page": 100}
yield dlt.resource(
fetch_github_data(endpoint, params),
name=endpoint,
write_disposition="merge",
primary_key="id",
)
pipeline = dlt.pipeline(
pipeline_name='github_dynamic_source',
destination='duckdb',
dataset_name='github_data',
)
load_info = pipeline.run(github_source())
row_counts = pipeline.last_trace.last_normalize_info
Handle secrets
For the next step we'd want to get the number of repository clones for our dlt repo from the GitHub API. However, the traffic/clones endpoint that returns the data requires authentication.
Let's handle this by changing our fetch_github_data() first:
from dlt.sources.helpers.rest_client.auth import BearerTokenAuth
def fetch_github_data(endpoint, params={}, access_token=None):
url = f"{BASE_GITHUB_URL}/{endpoint}"
return paginate(
url,
params=params,
auth=BearerTokenAuth(token=access_token) if access_token else None,
)
@dlt.source
def github_source(access_token):
for endpoint in ["issues", "comments", "traffic/clones"]:
params = {"per_page": 100}
yield dlt.resource(
fetch_github_data(endpoint, params, access_token),
name=endpoint,
write_disposition="merge",
primary_key="id",
)
...
Here, we added access_token parameter and now we can use it to pass the access token to the request:
load_info = pipeline.run(github_source(access_token="ghp_XXXXX"))
It's a good start. But we'd want to follow the best practices and not hardcode the token in the script. One option is to set the token as an environment variable, load it with os.getenv() and pass it around as a parameter. dlt offers a more convenient way to handle secrets and credentials: it lets you inject the arguments using a special dlt.secrets.value argument value.
To use it, change the github_source() function to:
@dlt.source
def github_source(
access_token: str = dlt.secrets.value,
):
...
When you add dlt.secrets.value as a default value for an argument, dlt will try to load and inject this value from different configuration sources in the following order:
- Special environment variables.
secrets.tomlfile.
The secret.toml file is located in the ~/.dlt folder (for global configuration) or in the .dlt folder in the project folder (for project-specific configuration).
Let's add the token to the ~/.dlt/secrets.toml file:
[github_with_source_secrets]
access_token = "ghp_A...3aRY"
Now we can run the script and it will load the data from the traffic/clones endpoint:
...
@dlt.source
def github_source(
access_token: str = dlt.secrets.value,
):
for endpoint in ["issues", "comments", "traffic/clones"]:
params = {"per_page": 100}
yield dlt.resource(
fetch_github_data(endpoint, params, access_token),
name=endpoint,
write_disposition="merge",
primary_key="id",
)
pipeline = dlt.pipeline(
pipeline_name="github_with_source_secrets",
destination="duckdb",
dataset_name="github_data",
)
load_info = pipeline.run(github_source())
Configurable sources
The next step is to make our dlt GitHub source reusable so it can load data from any GitHub repo. We'll do that by changing both github_source() and fetch_github_data() functions to accept the repo name as a parameter:
import dlt
from dlt.sources.helpers.rest_client import paginate
BASE_GITHUB_URL = "https://api.github.com/repos/{repo_name}"
def fetch_github_data(repo_name, endpoint, params={}, access_token=None):
"""Fetch data from GitHub API based on repo_name, endpoint, and params."""
url = BASE_GITHUB_URL.format(repo_name=repo_name) + f"/{endpoint}"
return paginate(
url,
params=params,
auth=BearerTokenAuth(token=access_token) if access_token else None,
)
@dlt.source
def github_source(
repo_name: str = dlt.config.value,
access_token: str = dlt.secrets.value,
):
for endpoint in ["issues", "comments", "traffic/clones"]:
params = {"per_page": 100}
yield dlt.resource(
fetch_github_data(repo_name, endpoint, params, access_token),
name=endpoint,
write_disposition="merge",
primary_key="id",
)
pipeline = dlt.pipeline(
pipeline_name="github_with_source_secrets",
destination="duckdb",
dataset_name="github_data",
)
load_info = pipeline.run(github_source())
Next, create a .dlt/config.toml file in the project folder and add the repo_name parameter to it:
[github_with_source_secrets]
repo_name = "dlt-hub/dlt"
That's it! Now you have a reusable source that can load data from any GitHub repo.
What’s next
Congratulations on completing the tutorial! You've come a long way since the getting started guide. By now, you've mastered loading data from various GitHub API endpoints, organizing resources into sources, managing secrets securely, and creating reusable sources. You can use these skills to build your own pipelines and load data from any source.
Interested in learning more? Here are some suggestions:
- You've been running your pipelines locally. Learn how to deploy and run them in the cloud.
- Dive deeper into how dlt works by reading the Using dlt section. Some highlights:
- Set up "last value" incremental loading.
- Learn about data loading strategies: append, replace and merge.
- Connect the transformers to the resources to load additional data or enrich it.
- Customize your data schema—set primary and merge keys, define column nullability, and specify data types.
- Create your resources dynamically from data.
- Transform your data before loading and see some examples of customizations like column renames and anonymization.
- Employ data transformations using SQL or Pandas.
- Pass config and credentials into your sources and resources.
- Run in production: inspecting, tracing, retry policies and cleaning up.
- Run resources in parallel, optimize buffers and local storage
- Use REST API client helpers to simplify working with REST APIs.
- Explore destinations and sources provided by us and community.
- Explore the Examples section to see how dlt can be used in real-world scenarios